
의공학교실 김남국
(서울아산병원 융합의학과/영상의학과) 교수
◆인공지능 개념
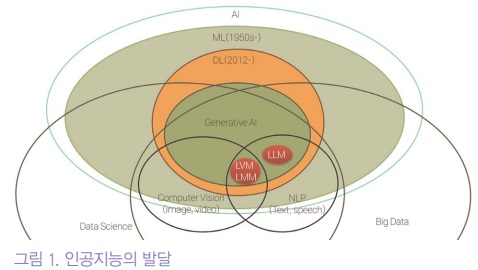
그림1은 인공지능의 개념을 설명하는 벤 다이어그램이다.
인공지능의 역사를 간단히 소개하면, 1950년대 초반, 기계 학습 개념이 소개된 이후 급속도로 발전하여, 2012년 딥러닝을 이용한 AlexNet이 이미지넷 챌리지에서 기존의 방법보다 훨씬 뛰어난 성능을 보여주면서, 본격적으로 시작되었다.
초기에는 인간의 시각발달을 모방한 Convolutional Neural Net(CNN)을 지도학습 계열로 학습하는 방법이 주로 연구되었지만, 2018년 이후로 더 이상 성능이 오르지 않는 문제와 인간의 언어를 특정 공간에 의미있게 맵핑 할 수 있는 Word2Vec (2012)등의 연구, Attention을 통한 장문의 언어 번역 등 자연어 처리 분야에서 생성된 다양한 학습 기법들을 통해 점점 생성형 인공지능 방향으로 발전하기 시작했다.
이러한 발전은 상당부분 어린아이나 동물의 시각, 언어 중추의 발달과 인지발달 과정을 모방하는 방식에서 시작되었다.
2023년경 이를 기반으로 인간의 언어를 이해하는 유연한 대화를 할수 있는 GPT 3.5 등의 초거대 언어모델의 성공으로 말미암아 본격적인 인공지능 혁명이 시작되었다.
최근에는 초거대언어모델을 더 잘 학습하기 위해 시각-언어모델 (Language-Vision Model; LVM), 대규모멀티모달모델 (Large-scale Multimodal Model; LMM) 등으로 발전하고 있는 상황이다.
이런 AI 기술은 의료 진단, 신약개발, 치료 계획 및 관리 등 다양한 의료 분야에서 혁신적인 도구로 자리매김하기 위해 노력하고 있고, 일부는 이미 기존의 직업에 영향을 줄 수 있는 상황이 되어, 공존에 대한 논의가 필요한 상황이다.
◆인공지능 계통
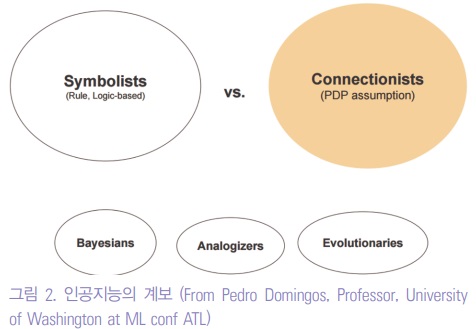
그림2는 지금까지 연구되고 있는 다양한 인공지능의 계통을 보여 주고 있다.
다양한 인공지능 방법론중에 성공적으로 결과물까지 나온 방법은 규칙과 3단 논법 등을 이용한 Symbolism과 인간의 신경망의 병렬분산처리 (Parallel Distributed Processing; PDP assumption)가 지능을 만들 수 있다는 Connectionism이 있다.
Connectionism은 Ivan P. Pavlov (1849-1936)의 유명한 개실험을 시작으로 행동주의 심리학자들이 자극과 반응의 관계형성(association forming)이 리워드를 기반으로 강화되거나 약해진다는 것에 기반하고 있다.
◆결정 과정
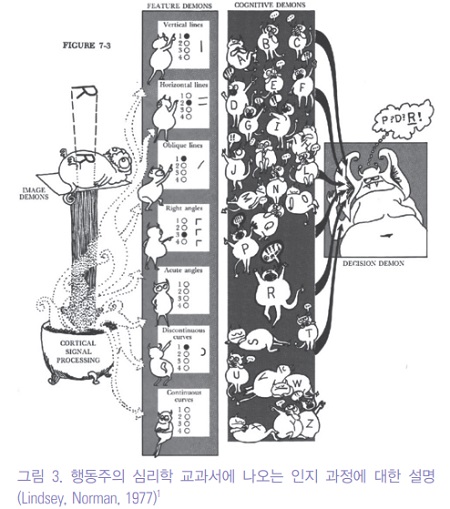
그림 3에서 볼 수 있듯이, 1977년 교과서에 나오는 인지 과정에 대한 설명은 R이라는 글자를 영상데몬 (Image Demons)이 대뇌피질처리 (Cortical signal processing)를 통해서 시그널로 바꾸어서, 특징을 뽑는 데몬 (Feature Demons)이 수직선, 수평선, 사선, 각도 등을 뽑고, 다양한 인지데몬 (Cognitive Demons)이 이런 특징에 맞는 글자를 평가한 후, 결정데몬 (Decision Demo)이 가까운 여러 글자중에 R이라고 결정한다.
이는 지금의 시각 딥러닝 방법중에 하나인 합성곱신경망(Convolutional Neural Net; CNN)과 놀라운 유사성을 보여주고 있다.
◆초거대언어모델 회사들…효율적인 모델 연구 중
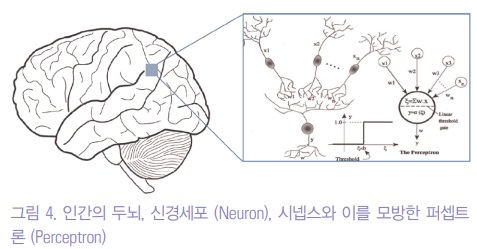
인간의 뇌는 약 천억개의 신경세포 (Neuron)로 구성되어 있으며, 하나의 신경세포가 다른 신경세포 천개에서 만개와 연결된다 (그림 4).
각 세포의 연결부위를 시넵스라고 하는데, 인간의 뇌에 약 100~1000조개 정도 있을 것으로 예측된다.
시넵스에서 다양한 신경전달물질 (Neuronal Transmitter)과 억제성 신경전달물질 (Neuronal Inhibitor) 등을 통하여 자극과 반응의 관계형성을 강화되거나 약화하게 되는 것이 알려졌다.
특정 신경세포에 자극이 비선형적으로 역치를 넘으면 이를 다른 신경세포에 전달하는 형식으로 동작된다.
따라서, 여기서 바뀌는 것은 시넵스를 통한 자극-반응 관계의 강화나 약화이고, 이게 지능의 본질이라고 보는 것이 Connectionism이다.
이것에 자극을 받아서 제안된 퍼셉트론은, 다양한 인풋 (x)에 각각 가중치 (weights)를 곱하여 통합하고, 활성화 함수 (Activation function)을 이용하여 아웃풋 (y)을 출력하는 형태로 작동된다.
따라서 아주 똑같지는 않지만, 퍼셉트론은 학습을 가중치를 업데이트 하는 방식으로 하기 때문에, 가중치가 인간의 뇌의 시넵스라고 볼 수 있다.
또한 사람은 생체 전기를 사용하므로 컴퓨터의 전기 (3×108 m/s)보다 훨씬 늦은 120 m/s 정도이다.
인간의 뇌는 병렬, 분산 처리를 할뿐더러 비선형적 신호처리를 한다고 할 수 있다.
지금까지 개발된 GPU 기반의 초거대 인공지능은 가장 큰 모델이 약 1.7조개 (GPT4 초기모델)의 가중치를 사용한다고 알려져 있고, 인간의 뇌와 같이 병렬, 분산처리를 할 수 있다.
하지만, 지금 가장 다른 것은 효율성이라 할 수 있다.
인간의 뇌 하나는 약 0.5kWh 정도의 에너지를 필요로 하지만, 상업화된 초거대 인공지능은 하루 2억건의 요청에 응답하는데 약 50만 kWh정도 사용하고 있다고 한다 .
따라서, 초거대언어모델 회사들은 최적화하고 전기 소모를 줄이는 효율적인 모델에 대한 연구를 하고 있다.
◆딥러닝 교육
인간의 뇌와 유사성이 있는 퍼셉트론과 이를 다층으로 쌓아서 만든 딥러닝을 어떻게 학습하는 것이 좋은지에 대한 많은 실험을 통한 통찰이 있었다.
특히 인간이 만든 정답을 교육하는 지도학습 (Supervised learning)은 초기에는 쉽게 성공적으로 다양한 딥러닝 모델을 학습시킬 수 있었지만, 인간이 만든 정답이 항상 맞지 않는다는 점, 대량의 정답을 만드는 것이 힘들다는 점, 비용이 많이 든다는 점 뿐 아니라, 더 큰 문제는 딥러닝 모델이 너무 쉽게 배우기 때문에 특정 데이터에 과적합 (Overfitting) 할 수 있다는 문제들이 제기되기 시작했다.
따라서 이를 해결하기 위하여 자기지도학습 (Self-supervised learning), 비지도학습 (Unsupervised learning)등의 다양한 방법이 제안되었다.
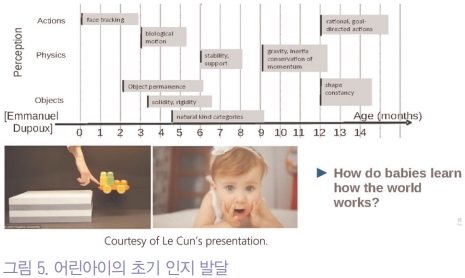
이는 어린아이나 어린 동물이 아무런 도움도 없이 언어중추, 시각 중추를 발달할 수 있다는 점에서 착안해서 언어를 배울 때 다음 단어를 듣는 것만 교육한다거나, 시각을 배울 때 같은 것과 다른 것만 학습하면 초기의 지능을 만드는데 충분하다는 것에 기반하고 있다 (그림 5). 또한 이를 통해 대량의 데이터를 레이블 없이 학습할수 있다는 장점이 있다.
◆딥러닝 모델…교육 인식 변화
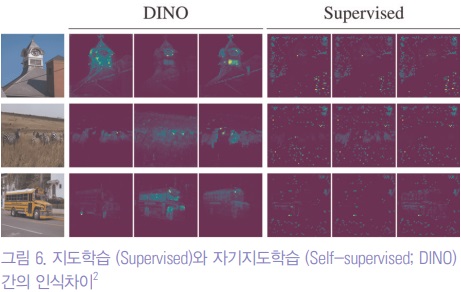
그림 6과 같이 지도학습을 통해 학습된 딥러닝 모델의 판단을 보여주는 활성맵 (Activation map)은 의미가 없는 부분에 과도한 집착을 보여주는 반면, 자기지도학습을 통한 활성맵은 모델이 영상의 핵심을 잘 파악하고 있는 것을 보여준다.
이는 딥러닝 모델을 어떻게 교육해야 하는지에 대한 많은 인식의 변화를 가져왔다.
이를 이해하기 위해서는 일단 표현학습 (representation learning)을 알아야 한다.
또한, 초거대언어모델을 잘 이해하기 위해서 언어 인공지능 모델을 발전 역사를 따라서 설명해 보겠다.
◆Distributed representation제안

그림 7에서 볼 수 있듯이 특정 단어를 unique하게 맵핑하는 one-hot encoding 방법은 단어 개수에 따라 vector가 커지는 문제를 차치하고도, 이 vector를 가지고 내적 등을 계산하면 모두 0이 나오기 때문에 이런 표현공간 (representation space)은 학습하기가 불가능하다.
따라서, 제프리 힌튼의 distributed representation은 위치가 의미가 있는 distributed encoding을 해야 한다는 제안이다. 제안된 시기가 1984년을 생각할 때 뛰어난 통찰이라고 생각한다.
◆표현공간 및 의미
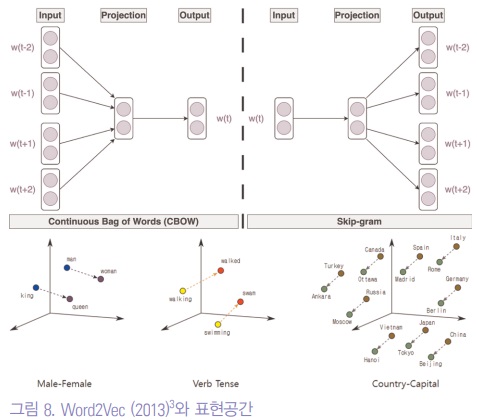
2013년 구글에서 제안한 Word2Vec는 연속된 5단어 중 주변의 4단어를 이용하여 가운데 단어를 맞추는 테스크와 가운데 단어 하나를 이용하여 반대로 주변 4단어를 맞추는 것을 학습시키는 모델이다 (그림 8).
이 모델은 약 16억개의 데이터셋으로 학습이 되었는데, 비슷한 문맥에서 같이 등장하는 경향이 있는 단어들은 비슷한 의미를 가진다는 분포 가설을 기반한 것이다.
결과는 이렇게 학습된 단어들이 표현공간 (representation space)에서 특별한 의미를 가지게 된 것이다.
그림 8을 보면 man-woman, king-queen 등이 공간에서 의미있게 맵핑됨을 알 수 있다. 또한, 이렇게 표현된 단어의 DistributedVector들 간의 내적이나 외적 등이 의미를 가지게 되었다.
◆자연어처리 대표적 문제 ‘번역’
자연어처리에 대표적인 문제는 번역이었다.
번역은 학습데이터도 충분하고, 상업적 가치도 많은 분야이다.
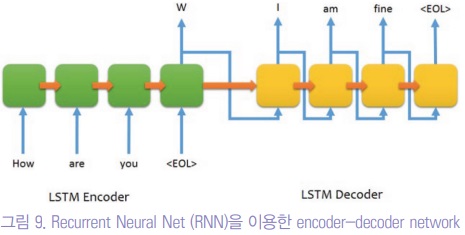
자연어는 순서가 있기 때문에 순서를 중요시하는 Recurrent Neural Net (RNN)을 이용한 encoder-decoder network이 제안되었으나, 이 네트워크는 오래된 (멀리 떨어진) 정보는 망각하는 치명적인 단점이 있었다.
따라서, 이를 해결하기 위해 각 단어를 처리할때마다 모든 다른 단어를 참고 (attention)해서 Attention score를 계산하는 방식으로 긴 문장을 더 잘 번역할 수 있게 되었다.
◆언어 번역 → 다른 지식으로 확대 가능
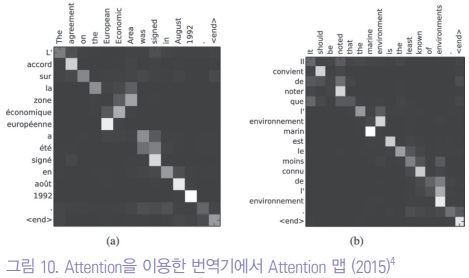
그림 10은 Attention을 이용하여 단어들 간의 attention을 보여주는 것이다.
이를 통한 언어 번역에 성능이 월등하게 좋아지게 되었다.
순서를 대부분 따라가지만, 불어와 영어의 어순 차이나, 관련된 주변부 단어의 attention이 잘 표현되고 있다.
이것은 단지 언어의 번역 뿐 아니라, 어떤 지식이라도 서로 매칭되는 학습데이터만 있다면, 특정 지식의 다른 지식으로의 ‘번역’으로 확대될 수 있다.
◆Transformer 구조
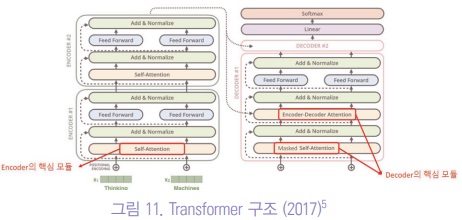
2017년에 앞의 RNN의 attention 개념을 확장하여 구글에서 ‘attention is all you need’라는 중요한 논문을 출간하였다.
여기서는 레이블이 필요없는 self-attention을 통해서 인공지능을 학습할 수 있다는 transformer 구조를 제안하였다.
이 모델은 지금까지 모든 거대 언어모델 등의 기반으로 사용되고 있다.
Transformer는 Encoder-Decoder Network으로 설계되어 있고, self-attention을 병렬로 배울 수 있게 설계되었다. 특히 Encoder나 Decoder를 각각 따로 학습할 수도 있다.
◆Query, Key, Value와 self-attention
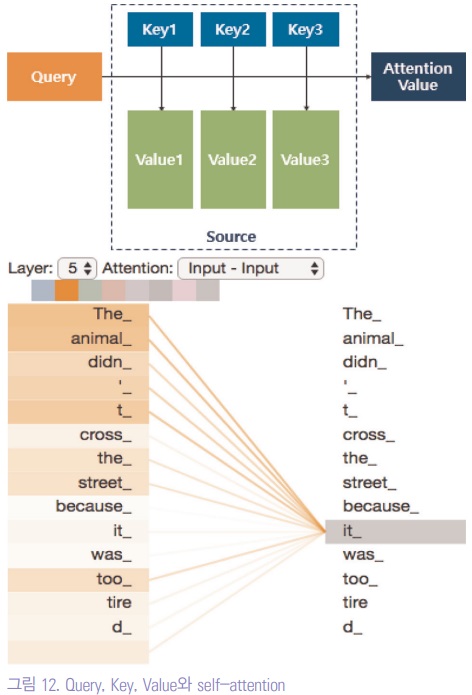
정보이론에서 정보를 일반적으로 다룰 수 있게 만든 Key-Value와 Query를 이용하여, Query에 가장 가까운 Key의 Value를 이용하여 Attention Value를 계산하여, Self-attention을 스스로 배울 수 있게 하였다.
특히 각각 단어들이 문장 내에서 다른 단어를 얼마나 attention하는지를 배울 수 있는 모델이다.
1. https://www.sciencedirect.com/book/9780124509603/
human-information-processing
2. Emerging properties in self-supervised vision transformers.
ICCV 2021 (pp. 9650-9660).
3. arXiv:1301.3781, Efficient Estimation of Word Representations
in Vector Space, Tomas Mikolov, Google
4. Neural machine translation, ICLR 2015, Dzmitry Bahdanau,
KyungHyun Cho, Yoshua Bengio
5. arXiv:1706.03762, Attention Is All You Need, Google 2017
(05505) 서울시 송파구 올림픽로 43길 88 울산대학교 의과대학 02-3010-4207, 4208, 4209
Homepage https://eletter.ulsan.ac.kr/main
홈페이지 문의 : wj0216@ulsan.ac.kr, 동문회 문의 : esmoon@ulsan.ac.kr